

Privacy in digital contact tracing
Hundreds of millions of downloads, and yet no serious privacy breaches: The privacy success of decentralized contact tracing apps has far-reaching implications for the future of digital health.

This is part 2 of a 4+1 series on digital contact tracing. You can read the previous parts here:
Part 0: Digital Contact Tracing - a mini series in 4(+1) parts
Part 1: Why contact tracing needs to go digital
Privacy for proximity tracing
After the epidemiological potential of digital contact tracing was established, groups around the world raced to develop a technical protocol for it. In what follows, I will briefly explain one of those protocols, the “decentralized, privacy preserving proximity tracing” protocol, or DP3T. I will put the focus on DP3T because it heavily inspired the development of the protocol that eventually made it into your phone: the Google and Apple Exposure Notification, or GAEN, system (for full transparency, I should also note that I was part of the team that developed DP3T). DP3T was preceded by an attempt called the “pan-european privacy preserving proximity tracing” protocol, or PEPP-PT, but DP3T split off due to fundamental differences about the technological architecture. Like PEPP-PT, DP3T was driven by the desire to have a solution that works across political borders. But the key aspect about DP3T was its decentralized nature, which aimed to prevent all the risks stemming from centralized systems.
In DP3T, a mobile phone continuously broadcasts an ephemeral, pseudo-random ID via Bluetooth Low Energy (BLE). At the same time, the phone also records the pseudo-random IDs from smartphones in close proximity. The proximity itself is estimated using the strength of the recorded BLE signal. While this distance estimate is imprecise, it nevertheless provides a sufficiently accurate assessment of the proximity (at the time, there was substantial debate about the incapability of BLE signals to obtain an accurate distance measure of 2 meters, which completely ignored that the 2 meters travel distance for droplets was already a highly uncertain estimate).
Importantly, before any diagnosis of COVID-19, all the data remains on the phone. Upon a positive COVID-19 test, a user can choose to share with a central server all the pseudo-random IDs that were broadcast during the infectious period. All users of the system regularly download such “infected” pseudo-random IDs from the central server to locally check (i.e. on their own phone) if they have been exposed, that is if they have been in contact with a positively tested person during their infectious period. If that is the case, the app can notify the person of the exposure.
This protocol was called decentralized because, even though a central server was part of the system, all the critical data, and the decision making, remains decentralized on the phones. This was in contrast to proposed protocols that were centralized, meaning that contact data would be available on the central server, where the decision-making about who to warn about an exposure would occur:
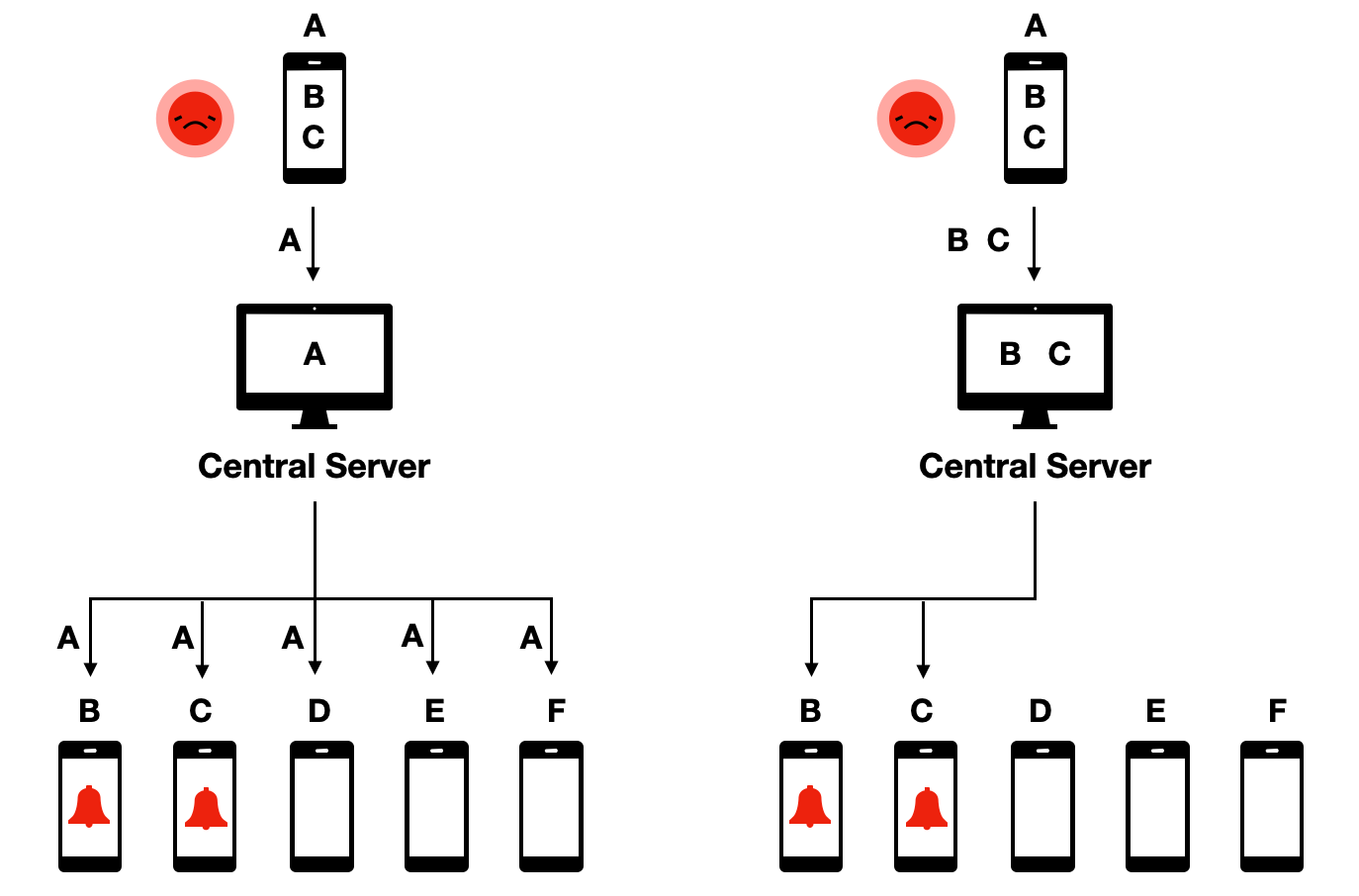
The decentralized protocol had a number of properties that made it highly desirable from a privacy point of view. First, it ensured data minimization, given that all sensitive contact data stayed in the hands of app users, rather than being accessible to a central authority. Second, and as a consequence, it minimized the risk of data abuse, because nobody would be able to get access to the data as it was completely distributed decentrally on users’ phones. Third, it made did not allow to track users, because central authorities would not even know that people are using the app unless they voluntarily declared themselves as tested positive. Fourth, it allowed for graceful dismantling - once users decided to stop using the app, the system would stop to exist, as no relevant data was stored on a central server that could be leveraged for further contact tracing usage.
The system also has two disadvantages which are important to note. First, because no contact information is transmitted to the central server, the central server cannot directly notify people who have been exposed. Instead, all users must constantly pull the information about infected IDs from the central server, and check locally on their phone if they have been exposed. This adds substantial bandwidth costs to the system. Second, because the central entity has no information about contacts, and their fate with respect to the exposure (i.e. if they later tested positive or not), it is not possible for the system to easily learn more about how to fine-tune parameters to optimize the system. These disadvantages can be circumvented in numerous ways. The bandwidth issue was mostly an efficiency issue, rather than a critical blocker. Arguably, the fact that the system could not learn more from the collected information was, from an epidemiological perspective, the biggest disadvantage. However, the argument that this wasn’t worth the privacy risk, and that the system could also learn more about the disease with the traditional contact tracing, ultimately won out. These kinds of trade-offs are inevitable in digital epidemiology, but understanding all advantages and disadvantages will allow us to find the most optimal solution (depending on how much weight we give to them).
The GAEN protocol follows the decentralized approach. Many health authorities would have preferred the centralized approach, largely out of a desire to collect relevant data and more rapidly understand better the efficacy of contact tracing. Nevertheless, most countries eventually built their apps based on the GAEN protocol. The main reason was that for apps to be effective, they needed to be able to trace contacts even if the phone was not switched on, i.e. in the background. The operating system of iPhones (iOS) however did not allow scanning for bluetooth signals in the background, mostly for security and efficiency reasons. This functionality was specifically built into GAEN for the purpose of contact tracing only. The implications of operating system providers setting the standards for public health applications continue to be cause for reflection and concern for many public health authorities.
From proximity tracing to presence tracing
Relatively soon after the beginning of the COVID-19 pandemic, it became clear that droplet transmission, which was initially thought to be the dominant transmission mode for the spread of COVID-19, was unable to explain certain patterns, such as the stark difference between indoor spreading (very common) and outdoor spreading (rare), superspreading events, or transmission chains that were known to be over longer distances than those possible with droplet transmission. As the evidence for aerosol transmission began to mount in the summer of 2020, it became also clear that digital proximity tracing - as digital contact tracing was called at the time - did not allow to notify people who had potentially been exposed through sharing the same airspace with an infectious person, but were not in close proximity to that person. For this reason, health authorities started to ask for information about presence at a given location, rather than only social, close proximity contacts, in situations where many people were gathering at the same indoor location, such as workplaces, restaurants, event venues, and others.
Presence tracing refers to the system by which a person can be notified of an exposure at a location at which the person was present. For airborne diseases spread through aerosols, where the infectious agent can linger in the air and travel over longer distances rather than just at close proximity, presence tracing is very important. Consider the scenario where a SARS-CoV-2 positive person (in their infectious period) enters a room. Virus-laden aerosols will be expelled, and travel to other parts of the room with the help of airflows. A susceptible person could thus be infected at a distance, even though she was never in close proximity to the infectious person. Furthermore, airborne aerosols don’t evaporate immediately, but can remain in the air for hours. Thus, a susceptible individual may be exposed to virus-laden aerosols expelled by an infectious person who has already left the location. Contact tracing based on proximity would not be able to capture either of these situations.
The illustration below shows the implications from an infectious disease transmission perspective. It considers a simple situation with two rooms, at two different timepoints. Assuming for simplicity that all individuals are in close proximity to another in a room, we can map the contact network based on close proximity alone (panel B), or based on a shared airspace (panel C). Note that because of the temporal aspect, the contact network in panel C becomes directional; for example, person 1 being in the room before person 6 means that person 1 could infect person 6, but not the other way around.
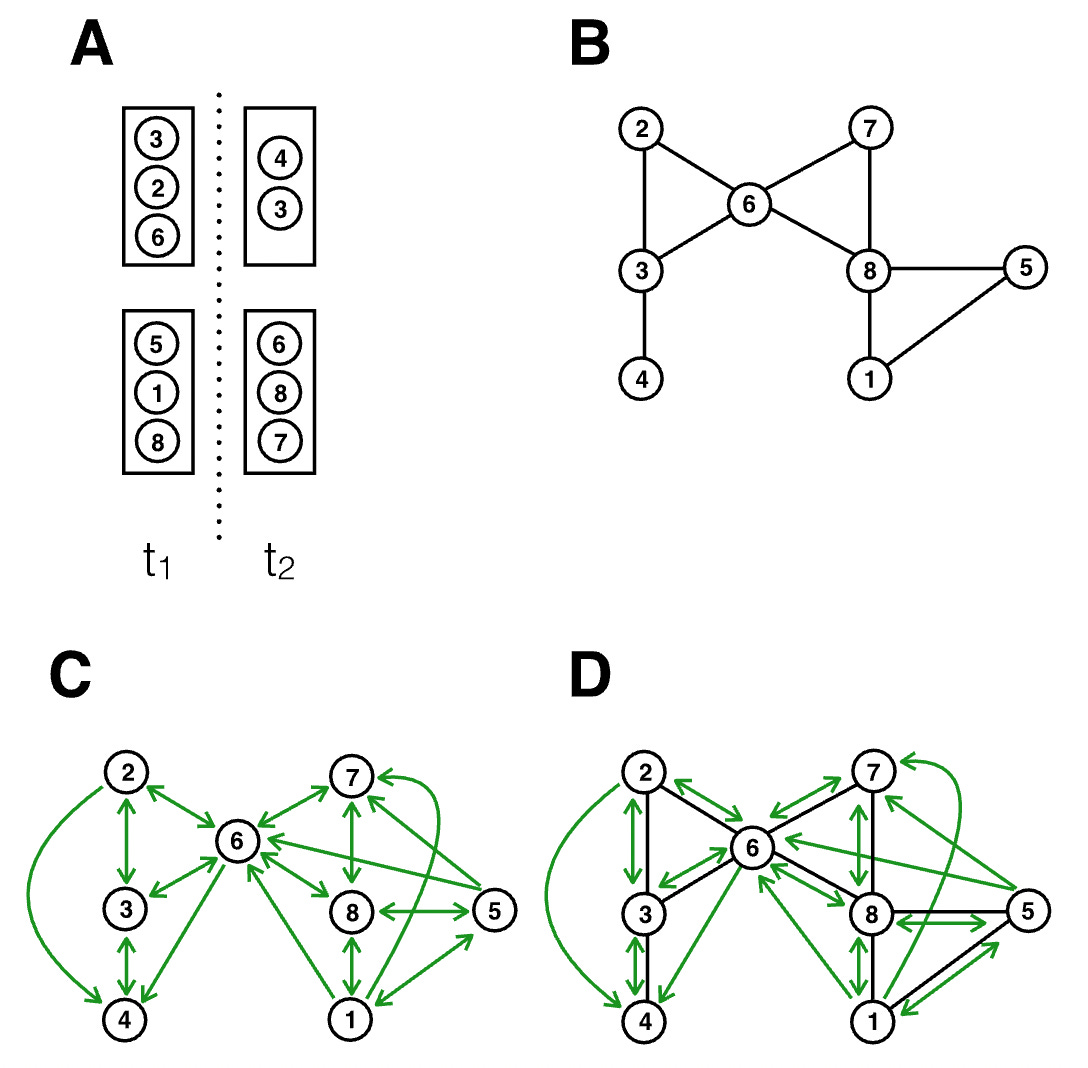
We can draw two observations from this illustration. First, there is substantial overlap between panels B and C, meaning that the exposure notifications that can be triggered from proximity tracing are still highly valuable. Close proximity transmission remains very important for disease transmitted by aerosols, because the concentration of aerosols is highest in close proximity to the expelling source (i.e. the infectious person). Second, there are many new transmission paths that are not captured by proximity considerations only. Indeed, relaxing the assumption in the figure that all interactions in a room are at close proximity would generate even more transmission paths (i.e. those at distance) than would not be captured by proximity alone.
Overall, proximity tracing thus captures a subset of the exposures that presence tracing would capture. But presence tracing casts quite a wide net - one infected person in a large room could potentially cause hundreds of exposure notifications, and to what extent the secondary attack rate would drop by extending proximity tracing to presence tracing is currently not well understood, largely because of the novelty of these systems and the lack of data.
Nonetheless, given the potential importance of SARS-CoV-2 transmission beyond close proximity, health authorities started to collect presence data in various forms. In many situations, paper-based lists were used as a low-tech solution. But relatively quickly, QR code scanning with mobile phones became a dominant mode of data collection. As with proximity tracing, this type of data collection, even though potentially useful for epidemiological purposes, has serious privacy implications. This is particularly true for systems where presence at a given location is recorded electronically and centrally with mobile phones, as it can allow for large-scale surveillance of who was where, and when.
Once again, we can think about protocols that would enable privacy-preserving presence tracing. One such protocol, called CrowdNotifier, was ultimately implemented in the German and the Swiss contact tracing apps (CoronaWarnApp and SwissCovid). Similar to proximity tracing, the system is designed to limit abuse by avoiding storing sensitive data centrally, and allows for graceful dismantling. We can again walk through the use case by imagining Alice visiting a venue, such as a restaurant, and scanning the QR code provided by the restaurant. At the same time, Bob, who doesn’t know Alice, also visits the restaurant. Bob sits at another table, and proximity tracing wouldn’t record a contact between them. However, as Bob will find out later, he is SARS-CoV-2 positive and presymptomatically contagious the night of his restaurant visit. Because the restaurant was tightly packed with limited ventilation, the chance of transmission from Bob to Alice is real, and Alice should get notified of the exposure so she can quarantine. While the concepts of privacy preservations are similar, there are some differences; if you are interested in the technical details about how the CrowdNotifier protocol achieves this, I recommend reading the CrowdNotifier paper. They key aspect is the same: data remains decentralized and is not stored centrally.
All known privacy problems came from centralized apps
Decentralized presence tracing did not become as widespread as decentralized contact tracing, for a number of reasons. First, presence tracing did not require OS updates, and thus the strict approval of Apple and Google. As a consequence, the diversity of solutions with respect to presence tracing was quite large, and most of these solutions - many coming from private actors - preferred the simplicity and the speed of a central system. Second, by the time presence tracing came into focus in the summer and fall of 2020, the pandemic was starting to gain even stronger momentum, as most countries had relaxed measures after the shock of the spring 2020 wave and a relatively calm summer. In the fall of 2020, the public health authorities and the healthcare system struggled under the severe burden of the very high number of cases, and much attention was put on the imminent availability of vaccines, rather than on additional technological development to improve contact tracing. Last but not least, a mix of security concerns and bodged communication in the spring and summer had made digital contact tracing apps less popular in the general population than initially hoped, and the enthusiasm to continue improving the technology had decreased substantially.
Occasionally, media reports surfaced about authorities misusing the apps. However, in all such cases, the cause was the centralized architecture of the presence tracing apps used. These apps often argued that people should put their trust in central authorities to not abuse the data. Yet, even with the best of intentions, centrally stored data can lead to catastrophic data leaks at scale. In addition, the availability of information-rich data in central places often turns out to be too attractive. For example, despite assurances to the contrary, contact tracing data in Singapore (who opted for a centralized approach) was used by police for criminal investigations on multiple occasions. Similarly, German police used data from the private, centralized presence tracing app Luca for criminal investigations (note that in contrast, the official government app, CoronaWarnApp, used decentralized presence tracing and never suffered from these problems). Such abuses of trust will unfortunately hamper widespread adoption of all contact tracing apps, impacting even those where privacy is built-in by design.
Implications
If you follow discussions about digital health, it sometimes feels like we are given a false choice: you can have an efficient digital health system, or you can have strong privacy. Pick one. What digital contact tracing showed is that this is clearly wrong. It is entirely possible to build digital health applications with reasonable privacy guarantees, all the while meeting the original objectives of the application. The illustration above shows this clearly by putting the decentralized and centralized approaches for digital contact tracing side by side. The result - alerting people of exposure - is the same in both. But the way this result is achieved is fundamentally different, with completely different privacy implications.
I would argue that this would apply to almost any digital health application. So why are decentralized digital health apps not more widespread? The problem is that when you build two apps that both do the same thing, but app A is privacy-preserving by design, while app B is not (privacy is “assured” by legal promises), app B will be much easier, and thus cheaper, to build. Decentralized systems are more complicated than centralized systems. They are more difficult to maintain and update. One would hope that market forces would drive the demand for decentralized digital health apps, but I am not overly optimistic about this. The past 20 years have shown how much privacy people are willing to sacrifice in exchange for convenience. For public health apps, the situation might be better: there may be much more demand - not at least through legal constraints - for decentralized approaches. But we do need to take into account the desire of public health systems to have access to insights that will help them do a better job.
This is why it is important to start developing decentralized systems now. It would be wrong to say “well, now that digital contact tracing is gone, let’s stop even thinking about such systems”. In the realm of public health, the goal of any digital health app should be to provide both privacy and functionality to users, as well as insights to the organizations deploying them. This is hard. It should not be done under the severe constraints of emerging health crises. Otherwise, when the next crisis hits, we will again have to deal with false choices between privacy and functionality. We were lucky this time, but having been very closely involved with the development, I have seen firsthand just what a close call it was, and how much resistance there was initially against decentralized approaches. Let’s prepare.