

How useful is OpenAI's new AI detection tool?
As we've learned during the early phase of the COVID pandemic, detecting rare things requires accurate tests.

OpenAI, the creator of ChatGPT (which I’m sure you’ve heard of), has just announced a tool to help detect AI text generation. OpenAI is aware that the tool is not yet particularly accurate. In their release notes, they write:
In our evaluations on a “challenge set” of English texts, our classifier correctly identifies 26% of AI-written text (true positives) as “likely AI-written,” while incorrectly labeling human-written text as AI-written 9% of the time (false positives).
What do these numbers mean?
Enter COVID-19.
As we’ve all learned during the COVID-19 pandemic, no test is perfectly accurate, and they can give wrong results in two ways.
They can tell you that you have something when you don’t - a false positive.
They can tell you that you don’t have something when you do - a false negative.
They can also give you the right result in two ways:
They can tell you that you have something when you do - a true positive
They can tell you that you don’t have something when you don’t - a true negative.
In an ideal world, there are no false positives, and no false negatives, and all tests are perfectly accurate. This is unfortunately quite far from reality. Many COVID-19 antigen tests, for example, had relatively high rates of false negatives, i.e. they would often give you a negative test result when you were in fact infected with SARS-CoV-2.
Why does this matter?
These things matter, but they matter even more so when the thing you are trying to detect is rare. This is true even when the test is quite accurate, but not perfectly so. The classical med school example goes as follows: In a given population, 0.9% of the population has a disease. You have a rather accurate test for the disease, with only 9% false positives, and 92% true positives. You test a random person in this population, and the test result is positive. What is the actual probability that the person truly has the disease?
Most people get this wrong. The answer is only about 8%.
Let us reformulate the problem and say we have 1000 people, of which 9 have the disease, and 991 don’t. Of the 991 non-diseased, 9% will get a false positive test - that’s about 89 people. Of the 9 people with the disease, 92% will get a correct positive test, which is about 8 people. Thus, a total of about 89 + 8 = 97 people will get a positive test, but only 8 of them actually have the disease. 8 divided by 97 is just a bit more than 8%. The key insight is that if most people getting tested do not have the disease to begin with, even a low frequency of false positives will “overwhelm” the results in the sense that having a positive test doesn’t mean all that much.
The OpenAI tool just announced isn’t nearly as accurate as our hypothetical medical test. It also produces 9% false positives, but it has only 26% true positives. But what we just learned is that it’s the false positives that will overwhelm the system when the “disease” is rare. In this case, the disease is an AI-generated text.
Let’s again reformulate this with absolute numbers. Say you are a school or a university, and 1000 students were asked to write a text. 3% tried to cheat and used ChatGPT to generate the text. We thus have 30 AI-generated texts and 970 human-generated texts. A teacher heard about the new AI detection tool by OpenAI, and runs the 1000 texts through it. Since we know the numbers, we can see what is going to happen:
Of the 970 human-generated texts, 9% (i.e. 87) will be falsely marked as AI-generated.
Of the 30 AI-generated texts, 26% (i.e. 8) will be correctly marked as AI-generated
In other words, the teacher will end up with 87 + 8 = 95 texts marked as AI-generated. In truth, only 8 of those have been generated by AI.
In other words: when the tool gives the teacher a positive (i.e “likely AI-generated”) result, the chance that the text was actually AI-generated is only about 8%. The vast majority of the texts with a positive result were human-generated. This means that about 92% of texts with an “AI-generated” label will be human-generated texts, falsely accused of having been generated by AI. Conversely, most AI-generated texts (22 out of 30) walk away with a false “human-written” stamp of approval.
This is not a criticism of the tool. Early steps, I get it. And indeed, I applaud OpenAI for being transparent about this. But if you are a teacher and you think you have just been handed a tool to deal with AI generation, please be aware that at this stage, the tool is rather useless in practice.
CODA
Fun fact: I ran this text through the classifier, and it said “The classifier considers the text to be very unlikely AI-generated.” Thank you 😅
Looking through the model card, I realized that things are actually slightly worse than described above. The model outputs are not “AI-generated” or “human-generated”, but are given as follows:
"Very unlikely to be AI-generated" corresponds to a classifier threshold of <0.1. About 5% of human-written text and 2% of AI-generated text from our challenge set has this label.
"Unlikely to be AI-generated" corresponds to a classifier threshold between 0.1 and 0.45. About 15% of human-written and 10% of AI-generated text from our challenge set has this label.
"Unclear if it is AI written" corresponds to a classifier threshold between 0.45 and 0.9. About 50% of human-written text and 34% of AI-generated text from our challenge set has this label.
"Possibly AI-generated" corresponds to a classifier threshold between 0.9 and 0.98. About 21% of human-written text and 28% of AI-generated text from our challenge set has this label.
"Likely AI-generated" corresponds to a classifier threshold >0.98. About 9% of human-written text and 26% of AI-generated text from our challenge set has this label.
In other words, the false positive and true positive rates are for the "Likely AI-generated" label only. Many more human-written texts (21%) would get the "Possibly AI-generated" label. Of course, the reverse is also true: more of the AI-generated texts (28%) would get a "Possibly AI-generated" label. But as described above, if most of the texts are human-generated to begin with, it’s the high number of false classifications of those that is the main problem.
CODA 2
To visually show the effect, I plotted the chance of a false AI labeling as a function of the fraction of truly AI-generated text. You can see that the chance of falsely accusing human-generated texts as “AI-generated” is just massive:
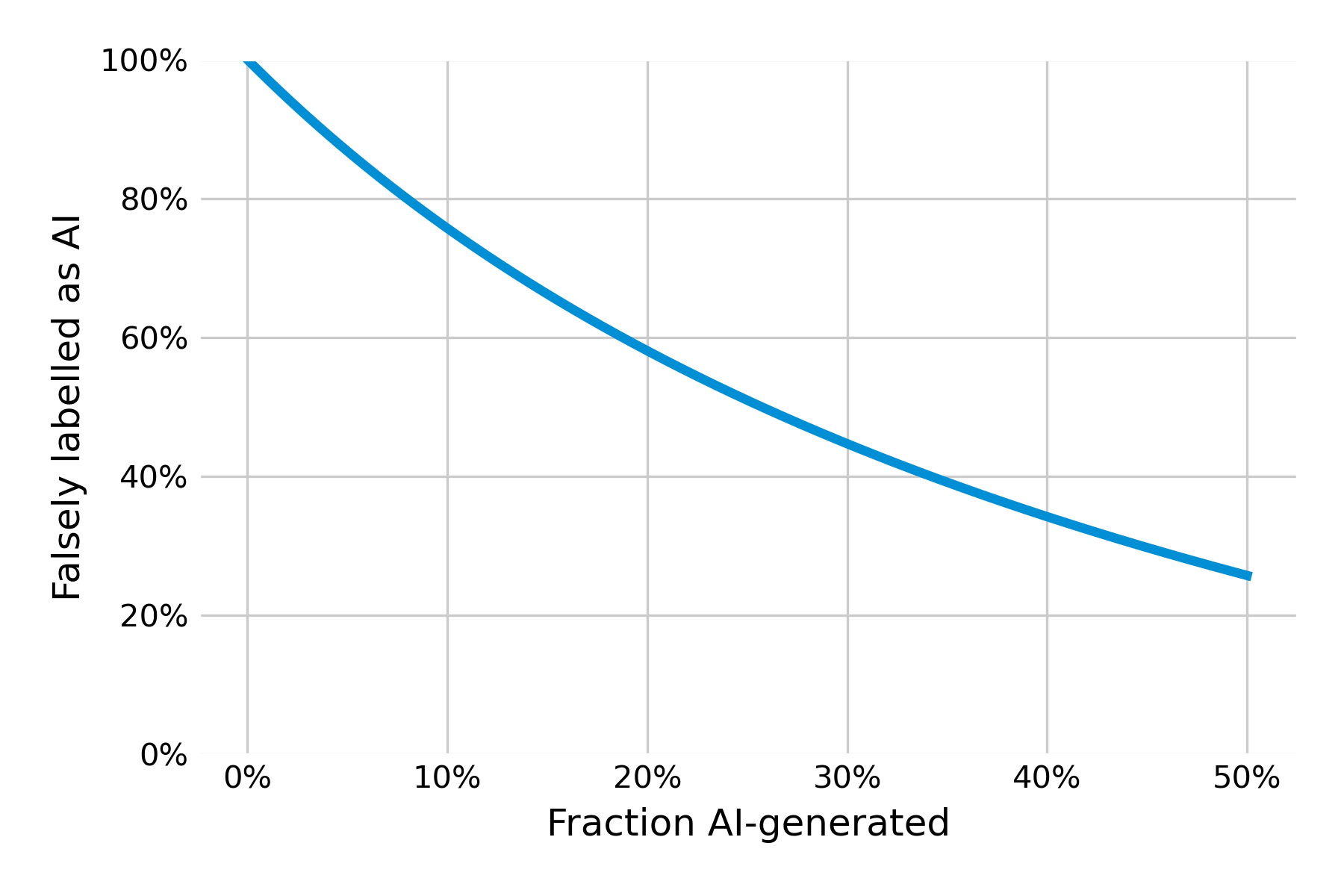
The problem though, is that it's not rare is it?
Who authored the MAGIC app?