

How AI can optimize health systems
NYUTron, a relative small (109 million parameters) language model pre-trained on clinical notes, improved health system predictions, demonstrating the potential of AI in the medical sector.

A new paper just published in Nature (open access) describes the creation of NYUTron, a comparatively small language model for medical applications. The model was pre-trained on unstructured clinical notes from electronic health records. After fine-tuning with an annotated data set, it was used for various clinical and operational predictions such as 30-day all-cause readmission, in-hospital mortality, comorbidity index, length of stay, and insurance denial prediction.
The model achieved 78.7–94.9% area under the curve (AUC), improving upon traditional models by 5.36–14.7% in the AUC. That’s quite an impressive increase, considering that no new data needed to be created, and that the improved predictions can likely be immediately used.
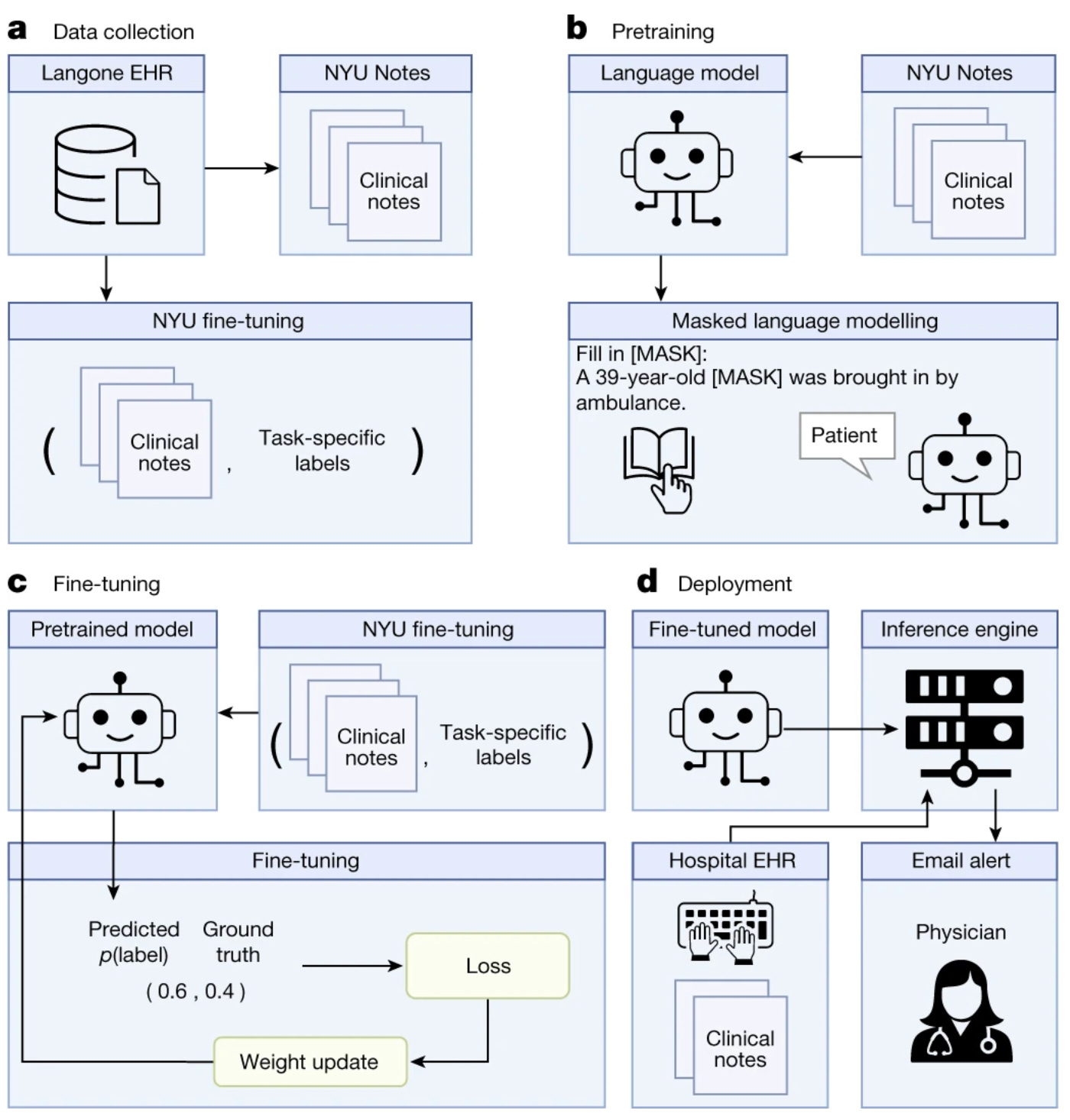
This is a very interesting application of a language model in the health domain. Notably, the paper uses a smaller, encoder language model pre-trained on highly tailored data, deviating from the LLM trend of employing massive, generative models pre-trained on large, non-specific datasets. The approach is computationally relatively intense (pre-training took three weeks on 24 NVIDIA A100 GPUs) but yields highly performant models after fine-tuning.
“It is a long-standing dream for physicians to have AI assistants observing care along with them and chiming in with predictions and advice.”
Jiang et al.
The authors are certainly right to caution against over-reliance on its predictions, and to call for continuous supervision to mitigate the risk of model drift over time. Indeed, a randomized controlled trial would be the ultimate test of such a system. However, the approach of training an AI model on the entirety of a large healthcare system's electronic health records is clearly a very promising advancement in applying modern natural language processing and deep learning techniques to improve healthcare quality.
Kudos to the authors for this excellent demonstration of the technology’s potential.
CODA: Where to find me
I’ll make it a habit in these posts to remind people where to find me:
Writing: I write another Substack on practical tips for interacting with large language models, called Engineering Prompts.
Curious about privacy issues dealing with LLM in health care. Does the paper address that?
👍, and spot on for our discussions here at https://aimi.stanford.edu/aimi23